Crawl Errors report (websites)
The Crawl Errors report for websites provides details about the site URLs that Google could not successfully crawl or that returned an HTTP error code.
Looking for the Crawl Status report for apps?
The report has two main sections:
- Site errors: This section of the report shows the main issues for the past 90 days that prevented Googlebot from accessing your entire site. (Click any box to display its chart.)
- URL errors: This section lists specific errors Google encountered when trying to crawl specific desktop or phone pages. Each main section in the URL Errors reports corresponds to the different crawling mechanisms Google uses to access your pages, and the errors listed are specific to those kinds of pages.
Site errors overview
In a well-operating site, the Site errors section of the Crawl Errors report should show no errors (this is true for the large majority of the sites we crawl). If Google detects any appreciable number of site errors, we'll try to notify you in the form of a message, regardless of the size of your site.
When you first view the Crawl Errors page, the Site errors section shows a quick status code next to the each of the three error types: DNS, Server connectivity, and robots.txt fetch. If the codes are anything other than a green check mark, you can click the box to see a graph of crawling details for the last 90 days.
High error rates
If your site shows a 100% error rate any of the three categories, it likely means that your site is either down or misconfigured in some way. This could be due to a number of possibilities that you can investigate:
- Check that a site reorganization hasn't changed permissions for a section of your site.
- If your site has been reorganized, check that external links still work.
- Review any new scripts to ensure they are not malfunctioning repeatedly.
- Make sure all directories are present and haven't been accidentally moved or deleted.
Low error rates
If your site has an error rate less than 100% in any of the categories, it could just indicate a transient condition, but it could also mean that your site is overloaded or improperly configured. You might want to investigate these issues further, or ask about them on our forum. We might alert you even if the overall error rate is very low — in our experience, a well configured site shouldn't have any errors in these categories.
Site error types
The following errors are exposed in the Site section of the report:
DNS Errors
What are DNS errors?
A DNS error means that Googlebot can't communicate with the DNS server either because the server is down, or because there's an issue with the DNS routing to your domain. While most DNS warnings or errors don't affect Googlebot's ability to access your site, they may be a symptom of high latency, which can negatively impact your users.
Fixing DNS errors
- Make sure Google can crawl your site.
Use Fetch as Google on a key page, such as your home page. If it returns the content of your homepage without problems, you can assume that Google is able to access your site properly. - For persistent or re-occuring DNS errors, check with your DNS provider.
Often your DNS provider and your web hosting service are the same. - Configure your server to respond to non-existent hostnames with an HTTP error code such as 404 or 500.
A website such asexample.comcan be configured with a wildcard DNS setup to respond to requests forfoo.example.com,made-up-name.example.comand any other subdomain. This makes sense in the case where a site with user-generated content gives each user account its own domain (http://username.example.com). However, in some cases, this kind of configuration can cause content to be unnecessarily duplicated across different hostnames, and it can also affect Googlebot's crawling.
DNS error list
| Error Type | Description |
|---|---|
| DNS Timeout |
Google couldn't access your site because your DNS server did not respond to the request in a timely manner. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. Check with your registrar to make sure your site is correctly set up and that your server is connected to the Internet. |
| DNS Lookup |
Google couldn't access your site because your DNS server did not recognize your hostname (such as www.example.com). Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. Check with your registrar to make sure your site is correctly set up and that your server is connected to the Internet. |
Server errors
What is a server error?
When you see this kind of error for your URLs, it means that Googlebot couldn't access your URL, the request timed out, or your site was busy. As a result, Googlebot was forced to abandon the request.
Fixing server connectivity errors
- Reduce excessive page loading for dynamic page requests.
A site that delivers the same content for multiple URLs is considered to deliver content dynamically (e.g.www.example.com/shoes.php?color=red&size=7serves the same content aswww.example.com/shoes.php?size=7&color=red). Dynamic pages can take too long to respond, resulting in timeout issues. Or, the server might return an overloaded status to ask Googlebot to crawl the site more slowly. In general, we recommend keeping parameters short and using them sparingly. If you're confident about how parameters work for your site, you can tell Google how we should handle these parameters. - Make sure your site's hosting server is not down, overloaded, or misconfigured.
If connection, timeout or response problems persists, check with your web hoster and consider increasing your site's ability to handle traffic. - Check that you are not inadvertently blocking Google.
You might be blocking Google due to a system level issue, such as a DNS configuration issue, a misconfigured firewall or DoS protection system, or a content management system configuration. Protection systems are an important part of good hosting and are often configured to automatically block unusually high levels of server requests. However, because Googlebot often makes more requests than a human user, it can trigger these protection systems, causing them to block Googlebot and prevent it from crawling your website. To fix such issues, identify which part of your website's infrastructure is blocking Googlebot and remove the block. The firewall may not be under your control, so you may need to discuss this with your hosting provider. - Control search engine site crawling and indexing wisely.
Some webmasters intentionally prevent Googlebot from reaching their websites, perhaps using a firewall as described above. In these cases, usually the intent is not to entirely block Googlebot, but to control how the site is crawled and indexed. If this applies to you, check the following:- To control Googlebot's crawling of your content, use the robots exclusion protocol, including using a robots.txt file and configuring URL parameters.
- If you're worried about rogue bots using the Googlebot user-agent, you can verify whether a crawler is actually Googlebot.
Server connectivity errors
| Error Type | Description |
|---|---|
| Timeout |
The server timed out waiting for the request. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| Truncated headers |
Google was able to connect to your server, but it closed the connection before full headers were sent. Please check back later. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| Connection reset |
Your server successfully processed Google's request, but isn't returning any content because the connection with the server was reset. Please check back later. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| Truncated response |
Your server closed the connection before we could receive a full response, and the body of the response appears to be truncated. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| Connection refused |
Google couldn't access your site because your server refused the connection. Your hosting provider may be blocking Googlebot, or there may be a problem with the configuration of their firewall. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| Connect failed |
Google wasn't able to connect to your server because the network is unreachable or down. It's possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Google is generally able to access your site properly. |
| Connect timeout |
Google was unable to connect to your server. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Googlebot is generally able to access your site properly. Check that your server is connected to the Internet. It's also possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
| No response |
Google was able to connect to your server, but the connection was closed before the server sent any data. Use Fetch as Google to check if Googlebot can currently crawl your site. If Fetch as Google returns the content of your homepage without problems, you can assume that Googlebot is generally able to access your site properly. It’s possible that your server is overloaded or misconfigured. If the problem persists, check with your hosting provider. |
Robots failure
What is a robots failure?
This is an error to retrieve your site's robots.txt file. Before Googlebot crawls your site, and roughly once a day after that, Googlebot retrieves your robots.txt file to see which pages it should not be crawling. If your robots.txt file exists but is unreachable (in other words, if it doesn't return a 200 or 404 HTTP status code), we'll postpone our crawl rather than risk crawling URLs that you do not want crawled. When this happens, Googlebot will return to your site and crawl it as soon as we can successfully access your robots.txt file. More information about the robots exclusion protocol.
Fixing robots.txt file errors
- You don't always need a robots.txt file.
You need a robots.txt file only if your site includes content that you don't want search engines to index. If you want search engines to index everything in your site, you don't need a robots.txt file—not even an empty one. If you don't have a robots.txt file, your server will return a 404 when Googlebot requests it, and we will continue to crawl your site. No problem. - Make sure your robots.txt file can be accessed by Google.
It's possible that your server returned a 5xx (unreachable) error when we tried to retrieve yourrobots.txtfile. Check that your hosting provider is not blocking Googlebot. If you have a firewall, make sure that its configuration is not blocking Google.
URL errors overview
The URL errors section of the report is divided into categories that show the top 1,000 URL errors specific to that category. Not every error that you see in this section requires attention on your part, but it's important that you monitor this section for errors that can have a negative impact on your users and on Google crawlers. We've made this easier for you by ranking the most important issues at the top, based on factors such as the number of errors and pages that reference the URL. Specifically, you'll want to consider the following:
- Fix Not Found errors for important URLs with 301 redirects. While it's normal to have Not Found (404) errors, you'll want to address errors for important pages linked to by other sites, older URLs you had in your sitemap and have since deleted, misspelled URLs for important pages, or URLs of popular pages that no longer exist on your site. This way, the information that you care about can be easily accessed by Google and your visitors.
- Update your sitemaps. Prune old URLs from your sitemaps, and if you add newer sitemaps that you intend to replace older ones, be sure to delete the old site map (not redirect it to the newer one).
- Keep redirects clean and short. If you have a number of URLs that redirect in a sequence (e.g. pageA > pageB > pageC > pageD), it can be challenging for Googlebot to follow and interpret the sequence. Try to keep the "hops" to a low number. Read more about Not followed.
Viewing URL error details
You can view URL errors in a variety of ways:
- Click Download to retrieve a list of the top 1,000 errors for that crawler type (e.g. desktop, smartphone).
- Use the filter above the table to locate specific URLs.
- See error details by following the link from individual URLs or Application URIs.
Mark URL errors as fixed
Once you've addressed the issue causing an error for a specific item, you can hide it from the list. You can do this singly or in bulk. Select the checkbox next to the URL, and click Mark as fixed. The URL will be removed from the list. However, this marking is just a convenience method for you; if Google's crawler encounters the error on the next crawl, the URL will reappear in the list the next time your URL is crawled.
URL error types
Common URL errors
| Error Type | Description |
|---|---|
| Server error |
When you see this kind of error for your URLs, it means that Googlebot couldn't access your URL, the request timed out, or your site was busy. As a result, Googlebot was forced to abandon the request. Read more about server connectivity errors. |
| Soft 404 |
Usually, when a visitor requests a page on your site that doesn't exist, a web server returns a 404 (not found) error. This HTTP response code clearly tells both browsers and search engines that the page doesn't exist. As a result, the content of the page (if any) won't be crawled or indexed by search engines. A soft 404 occurs when your server returns a real page for a URL that doesn't actually exist on your site. This usually happens when your server handles faulty or non-existent URLs as "OK," and redirects the user to a valid page like the home page or a "custom" 404 page. This is a problem because search engines might spend much of their time crawling and indexing non-existent, often duplicative URLs on your site. This can negatively impact your site's crawl coverage because your real, unique URLs might not be discovered as quickly or visited as frequently due to the time Googlebot spends on non-existent pages. If your page is truly gone and has no replacement, we recommend that you configure your server to always return either a 404 (Not found) or a 410 (Gone) response code in response to a request for a non-existing page. You can improve your visitors' experience by setting up a custom 404 page when returning a 404 response code. For example, you could create a page containing a list of your most popular pages, or a link to your home page, or a feedback link. But it's important to remember that it's not enough to just create a page that displays a 404 message. You also need to return the correct 404 or 410 HTTP response code. |
| 404 |
Googlebot requested a URL that doesn't exist on your site. Fixing 404 errorsMost 404 errors don't affect your site's ranking in Google, so you can safely ignore them. Typically, they are caused by typos, site misconfigurations, or by Google's increased efforts to recognize and crawl links in embedded content such as JavaScript. Here are some pointers to help you investigate and fix 404 errors:
If you don't recognize a URL on your site, you can ignore it. These errors occur when someone browses to a non-existent URL on your site - perhaps someone mistyped a URL in the browser, or someone mistyped a link URL. However, you might want to catch some of these mistyped URLs as described in the list above. |
| Access denied |
In general, Google discovers content by following links from one page to another. To crawl a page, Googlebot must be able to access it. If you're seeing unexpected Access Denied errors, it may be for the following reasons:
To fix:
|
| Not followed |
Not followed errors lists URLs that Google could not completely follow, along with some information as to why. Here are some reasons why Googlebot may not have been able to follow URLs on your site: Flash, JavaScript, active content Some features such as JavaScript, cookies, session IDs, frames, DHTML, or Flash can make it difficult for search engines to crawl your site. Check the following:
Redirects
|
| DNS error |
When you see this error for URLs, it means that Googlebot could either not communicate with the DNS server, or your server had no entry for your site. Read more about DNS errors. |
Mobile-only URL errors (Smartphone)
| Error | Description |
|---|---|
| Faulty redirects |
The Faulty redirect error appears in the URL Errors section of the Crawl > Crawl Errors page under the Smartphones tab. Some websites use separate URLs to serve desktop and smartphone users and configure desktop pages to direct smartphone users to the mobile site (e.g. m.example.com). A faulty redirect occurs when a desktop page incorrectly redirects smartphone users to a smartphone page not relevant to their query. A typical example of this occurs when all desktop pages redirect smartphone users to the homepage of the smartphone-optimized site. In the figure below, the redirects shown with red arrows indicate faulty redirects: 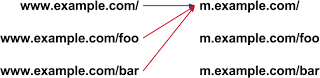
This kind of redirect disrupts users' workflow and can cause them to stop using the site and look elsewhere. Following are some tips to help you create a mobile-friendly search experience and avoid faulty redirects:
|
| URLS blocked for smartphones |
The "Blocked" error appears on the Smartphone tab of the URL Errors section of the Crawl > Crawl Errors page. If you get the "Blocked" error for a URL on your site, that means that the URL is blocked for Google's smartphone Googlebot in your site's robots.txt file. This may not necessarily be a smartphone-specific error (for example, the equivalent desktop pages may also be blocked). However, it often indicates that the robots.txt file needs to be modified to allow crawling of smartphone-enabled URLs. When the smartphone-enabled URLs are blocked, the mobile pages can't be crawled and because of this, they may not appear in search results. If you get the "Blocked" smartphone crawl error for URLs on your site, examine your site's robots.txt file and make sure that you are not inadvertently blocking parts of your site from being crawled by Googlebot for smartphones. For more information, see our recommendations. |
| Flash content |
The Flash content error appears in the URL Errors section of the Crawl > Crawl Errors page under the Smartphones tab. Our algorithms list URLs in this section as having content rendered mostly in Flash. Many devices cannot render these pages because Flash is not supported by iOS or Android versions 4.1 and higher. We recommend that you improve the mobile experience for your website by using responsive web design for your site, a practice recommended by Google for building search-friendly sites for all devices. You can learn more about this in Web Fundamentals, a comprehensive resource for multi-device web development. Whichever approach you take to address this issue, be sure to allow Googlebot access to all assets of your site (CSS, JavaScript, and images) and do not block them with robots.txt or by other means. Our algorithms need these external files to detect your site's design configuration and treat it appropriately. You can make sure our indexing algorithms have access to your site by using the Fetch as Google feature in Search Console. |
* Nguồn: Google Search Console